Citadel 2.0: Predicting Maliciousness
Introduction
In Citadel: Binary Static Analysis Framework, I put out a weekend project which used a bunch of different tools to profile a PE and pass it over to Defender for an additional check. See the following tools for the inspiration:
The goal is to give it a sample and then see if it's got any major red flags before deploying on an engagement. In its current state, it kind of gives you a boolean approach of is good or is bad which comes from the Windows Defender component. Then a few weeks ago, EMBER2024 - A Benchmark Dataset for Holistic Evaluation of Malware Classifiers was release which gave us LightGBM classifiers at joyce8/EMBER2024-benchmark-models on huggingface.co.
So why is this cool? Well, it allows us to use the models prediction functionality as seen in predict_sample.
In this blog, we will go over how EMBER prediction works, how its built into Citadel, and the entirely vibe-coded UI with Next.js.
tldr; Running Citadel
At the moment, Citadel relies on a python API to support the agent, then a node frontend. In future releases I'll combine the two. But for now, follow the installation steps in the README and script. Then run:
Python API:
uv run api/api.pyFrontend:
cd frontend
npm run devThen, you can access the UI at http://localhost:3000.
LightGBM
Before going into EMBER, Its worth doing a quick overview of LightGBM. In LightGBM: A Highly Efficient Gradient Boosting Decision Tree, researchers introduce a fast and scalable tool for machine learning. LightGBM groups data into buckets using a histogram-based method which saves memory and speeds up training. It builds decision trees by choosing splits that improve predictions most. This, in turn, boosts accuracy but requiring adjustments to avoid errors.
With GPU support, it handles big datasets for tasks like sorting or predicting, making it popular in data science for its speed and power. When we want to classify samples, this is a great solution.
EMBER
In 2018, the original EMBER dataset was released in EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models and elastic/ember by Elastic. Below is a quote from the GitHub explaining what EMBER is:
The EMBER dataset is a collection of features from PE files that serve as a benchmark dataset for researchers. The EMBER2017 dataset contained features from 1.1 million PE files scanned in or before 2017 and the EMBER2018 dataset contains features from 1 million PE files scanned in or before 2018. This repository makes it easy to reproducibly train the benchmark models, extend the provided feature set, or classify new PE files with the benchmark models.
As it states, EMBER's earlier version is a dataset consisting of 1.1 million PE files gathered around 2017 and 2018. It uses LIEF to extract its features and was a main driving force for what Citadel extracts. Looking in features.py, we can see this happening in the various classes.
Fast forward to 2024, and the dataset has been improved to include 3.2 million malicious
AND benign files from win32, win64, .net, apk, elf, and pdf
file formats. The following table is from File
Statistics:
| File Type | Malicious + Benign (Weekly) | Train Total | Test Total |
|---|---|---|---|
| Win32 | 30,000 | 1,560,000 | 360,000 |
| Win64 | 10,000 | 520,000 | 120,000 |
| .NET | 5,000 | 260,000 | 60,000 |
| APK | 4,000 | 208,000 | 48,000 |
| 1,000 | 52,000 | 12,000 | |
| ELF | 500 | 26,000 | 6,000 |
In Static Data Exploration of Malware and Goodware Samples, michaeljranaldo and I discussed how we gathered our samples and its (obviously) nowhere near as complete as Elastic's collection, but as a vendor, this should be obvious.
Implementing EMBER predictions
The implementation for the EMBER model in Python is pretty easy. The first thing is to map the models:
class FileType(IntEnum):
"""Enumeration of supported file types for EMBER analysis."""
UNKNOWN = 0
WIN32 = 1
WIN64 = 2
DOTNET = 3
APK = 4
ELF = 5
PDF = 6
MODEL_MAP = {
FileType.WIN32: "EMBER2024_Win32.model",
FileType.WIN64: "EMBER2024_Win64.model",
FileType.DOTNET: "EMBER2024_Dot_Net.model",
FileType.APK: "EMBER2024_APK.model",
FileType.ELF: "EMBER2024_ELF.model",
FileType.PDF: "EMBER2024_PDF.model",
}Then, use the huggingface library to download the model and return the path:
from huggingface_hub import hf_hub_download
def download_model(model_filename: str, model_dir: Path) -> Path:
"""
Download the model from the Hugging Face Hub.
:param model_filename: The name of the model to download.
:type model_filename: str
:param model_dir: The directory to save the model to.
:type model_dir: Path
:return: The path to the downloaded model.
:rtype: Path
"""
if Path(model_dir / model_filename).exists():
return Path(model_dir / model_filename)
try:
model_path = hf_hub_download(
repo_id="joyce8/EMBER2024-benchmark-models",
filename=model_filename,
local_dir=str(model_dir),
)
return Path(model_path)
except Exception as e:
logger.bad(f"Failed to download {model_filename}: {e}")
return NoneEach model will be put into the home directory so they can be reused:
MODEL_DIR = Path("~/.citadel/models").expanduser()That sorts out the models. The next thing is determining which aspect of the model map to return. This is done by using python-magic and some handling on the file header. With this, we can return an enum which points back to the map.
def detect_file_type(file_path: str) -> FileType:
"""
Detect the file type of a file.
:param file_path: The path to the file to detect the type of.
:type file_path: str
:return: The type of the file.
:rtype: FileType
"""
try:
mime_type = magic.from_file(file_path, mime=True)
with open(file_path, "rb") as f:
header = f.read(1024)
# simple file type detection
if mime_type == "application/pdf" or header.startswith(b"%PDF"):
return FileType.PDF
if mime_type == "application/zip" and file_path.lower().endswith(".apk"):
return FileType.APK
if b"AndroidManifest.xml" in header:
return FileType.APK
if header.startswith(b"\x7fELF"):
return FileType.ELF
if header.startswith(b"MZ"):
try:
pe = pefile.PE(file_path)
# check for .NET
if hasattr(pe.OPTIONAL_HEADER, "DATA_DIRECTORY"):
for entry in pe.OPTIONAL_HEADER.DATA_DIRECTORY:
if (
entry.name == "IMAGE_DIRECTORY_ENTRY_COM_DESCRIPTOR"
and entry.VirtualAddress != 0
):
return FileType.DOTNET
# check architecture
if pe.OPTIONAL_HEADER.Magic == 0x10B:
return FileType.WIN32
elif pe.OPTIONAL_HEADER.Magic == 0x20B:
return FileType.WIN64
except:
return FileType.WIN32
return FileType.UNKNOWN
except Exception as e:
logger.bad(f"Error detecting file type: {e}")
return FileType.UNKNOWNThat's all the noddy stuff out of the way, so let's look at how to actually do a prediction. A few wrapper functions in, we hit the main component:
model = lgb.Booster(model_file=str(model_path))
with open(file_path, "rb") as f:
file_data = f.read()
# thrember.predict_sample returns a float, not an object
score = thrember.predict_sample(model, file_data)
return EmberResult(
file_path=str(file_path.resolve()),
score=score,
model_name=model_path.name,
)First, we define and initialise the LightGBM Booster. Then, we open up the file to get the bytes and call the thrember.predict_sample function. Looking at this function, it uses the PEFeatureExtractor to create a vectorised feature set, then passes that into the models predict function:
def predict_sample(lgbm_model: lgb.Booster, file_data: bytes) -> float:
"""
Predict a PE file with an LightGBM model
"""
extractor = PEFeatureExtractor()
features = np.array(extractor.feature_vector(file_data), dtype=np.float32)
predict_result: np.ndarray = lgbm_model.predict([features])
return float(predict_result[0])Inside the Citadel repo, we have a scripts directory which contains predict.py, this script will fire off the prediction and return a JSON response:
{
"file_path": "/home/mez0/dev/citadel/samples/malware/01fed158eb8f666ce6c000c0771da0736e0efa373cbcb49f677c1fe7be6409f2.dat",
"score": 0.9992446985120035,
"prediction": "malicious",
"model_name": "EMBER2024_Win32.model"
}And that's gist of it. In the new UI section, I'll show how that's rendered on the frontend.
LLM Summary
The next thing I added was an LLM summary for the findings using OpenAI. At some point it would be cool to use different models, but OpenAI is the easiest to get going. If it finds the OPENAI_API_KEY environment variable, it will create a summary of the payload where it passes in key information, before firing it off to OpenAI – this is then embedded into the model and rendered on the UI. Below is some of the input passed to the LLM:
message = f"""
## Summary
### Metadata
- Payload SHA256: {payload.sha256}
- Payload Architecture: {payload.architecture}
- Payload Timestamp: {payload.timestamp}
- Payload Entropy: {payload.entropy}
### Scan Results
- Windows Defender result: {task.defender_result}
- Windows AMSI result: {task.amsi_result}
- Threat Names: {', '.join(task.threat_names)}
- ML Score: {task.ember_result.score} {task.ember_result.prediction}
- Similar TLSH Hashes: {len(task.similar_tlsh_hashes)}
### Yara Matches
{yara_summary}
### Capa Reports
{capa_summary}
### Function Mappings
{function_mapping_summary}
### Toolchain
{toolchain_summary}
### Certificates
{certificate_summary}
"""response = client.responses.create(
model="gpt-4o",
instructions="""
You are a malware researcher focusing on malware triage to determine whether a file is malicious or not.
You will be given metadata and scan results from a sample, and you must use it to determine whether the file is malicious or not.
You must provide a detailed explanation of your reasoning for your answer.
""",
input=message,
)And here is a sample response:
Based on the provided metadata, scan results, toolchain information, and certificates, here's a detailed analysis:
### Metadata and Scan Results:
1. **File Characteristics**:
- **SHA256**: Unique identifier for the file, showing its cryptographic hash.
- **Architecture**: x86, indicating a 32-bit application which is common for many executable files.
- **Timestamp**: Indicates the file was created in 2020, which can sometimes be a timestamp forgery tactic to evade detection.
- **Entropy**: 6.23, which is within the typical range for executable files. It suggests compression or encryption but is not excessively high to raise immediate suspicion.
2. **Security Tools and Scores**:
- **Windows Defender/AMSI Results**: No detections are explicitly shown, which suggests no known malicious patterns were detected by these tools.
- **ML Score**: 0.00197 labeled as benign. This suggests a very low likelihood of being malicious based on machine learning models.
- **Yara Matches**: No matches reported. This would be a significant indicator if any malicious patterns were detected.
- **Similar TLSH Hashes**: 0, indicating no detected similarities to known malicious files in the database.
### Capa Reports and Function Analysis:
1. **Capa Features**:
- **Hide Graphical Window**: Aligns with MITRE ATT&CK T1564/003 for defense evasion by hiding artifacts. This is a suspicious activity but not conclusively malicious alone.
- **Contain Loop**: This is a common programming pattern.
- **Read File via Mapping**: Common file operation, though it can be leveraged in malicious activities.
2. **Function Mappings**:
- Predominantly involve standard API calls for process and thread management, memory operations, and inter-thread communication.
- Use of functions like `IsDebuggerPresent` suggests anti-analysis or anti-debugging techniques, which are commonly used by malware.
- File mapping and memory management functions are routine but could be utilized in malicious contexts for stealth or resource manipulation.
### Toolchain Information:
- **Microsoft Visual C/C++ and other Microsoft tools**: Legitimate toolchains, but commonly used as they are widespread and versatile.
- **Authenticode Signatures**: Use of legitimate signing tools suggests an attempt to appear legitimate, though not conclusive on its own as signatures can be forged or misused.
### Certificates:
- Certificates issued by well-known authorities like DigiCert and Symantec provide a layer of legitimacy, but these can be stolen or misused.
- The presence of valid timestamps and certificates could imply an attempt to appear legitimate but doesn't rule out malice.
### Conclusion:
The file exhibits a mixture of potentially suspicious behaviors (such as hiding windows and checking for debuggers) but predominantly showcases benign traits, as indicated by the low ML score and lack of recognized malicious patterns or detections by Windows Defender and AMSI. While the intent behind some behaviors like hiding windows or anti-debugging techniques raises suspicion, the absence of direct evidence of malice in scans and the presence of legitimate certificates suggest it isn't overtly malicious.
**Final Assessment**: **Likely Benign**
While there are elements—such as potential defense evasion—that could be leveraged maliciously, they are not definitively harmful in the presented context. Continuous monitoring and behavioral analysis during execution are advised to ensure it does not exhibit malicious activity in different environments.I'm not entirely happy with the prompt, I think it needs to be more
definitive in its analysis. For example, I think this payload is
malicious - but it'll do for now.
Citadel UI 2.0
Okay, so... this UI is entirely vibe-coded and I proudly didn't write a single line of code. It's a Next.js application and and uses AG Charts.
I've tried to ensure that visual hierarchy and data storytelling is consistent throughout, but it's far harder than I expected. Here is the new dashboard:
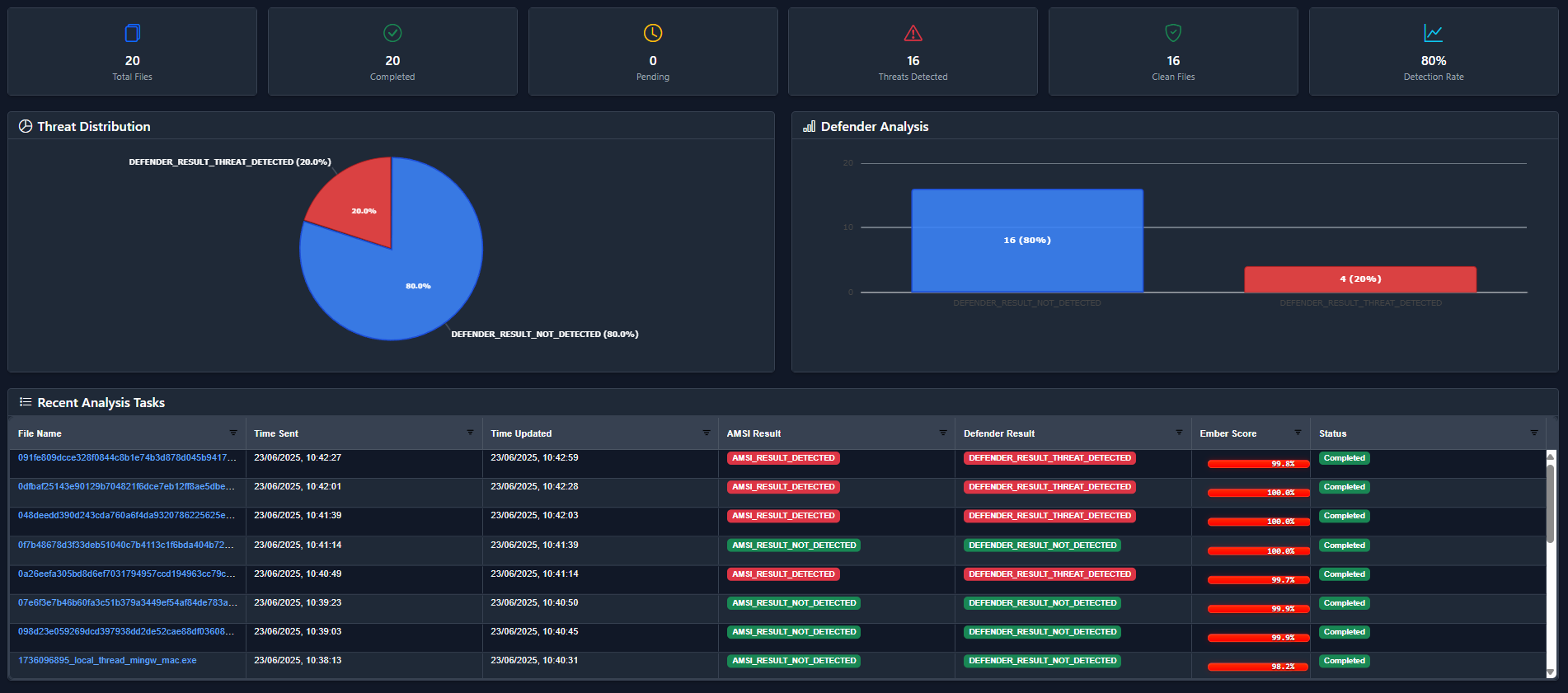
Clicking on the File Name will take you to the summary:
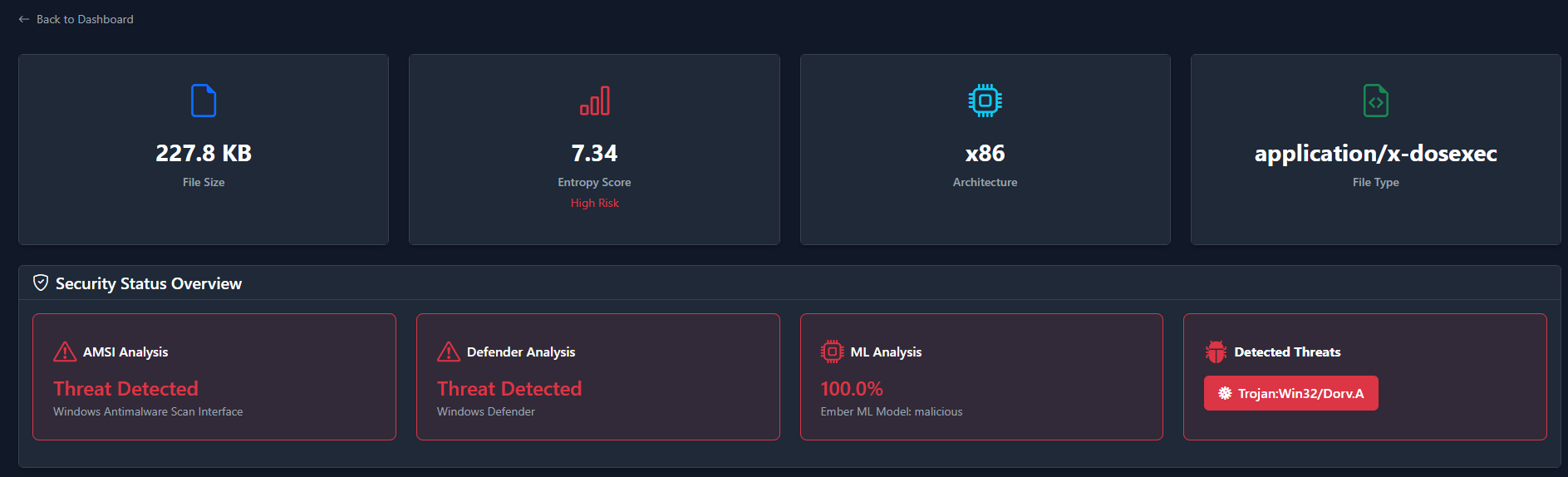
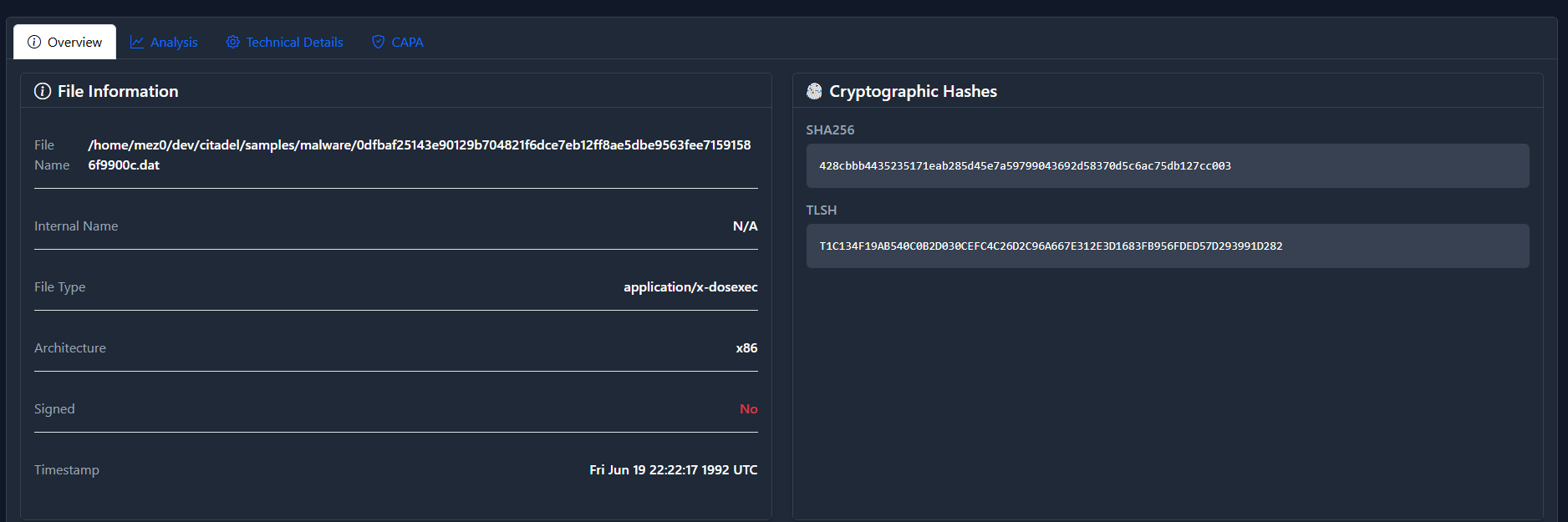
Here we have a lot of information and I've tried to put the most
relevant stuff at the top. So in this sample,
428cbbb4435235171eab285d45e7a59799043692d58370d5c6ac75db127cc003 is
considered 100% malicious by EMBER, and Defender identified it as
Trojan:Win32/Dorv.A.
Scrolling down this page, we get the AI Analysis Summary:
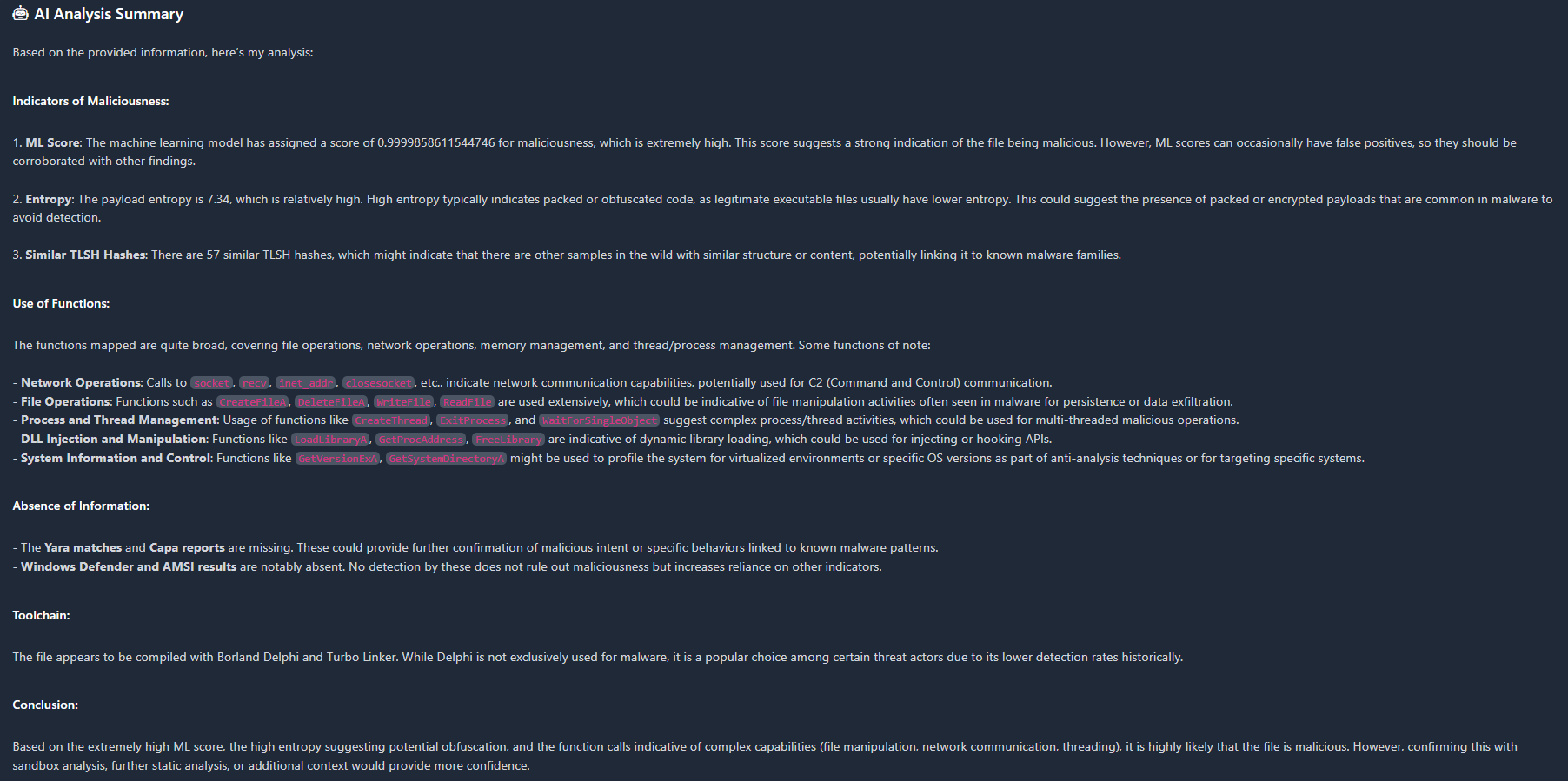
This is where it got difficult, under the Analysis tab – I've tried to help figure out where the binary may be malicious.
Scrolling down, the first thing we see is an Import Analysis :
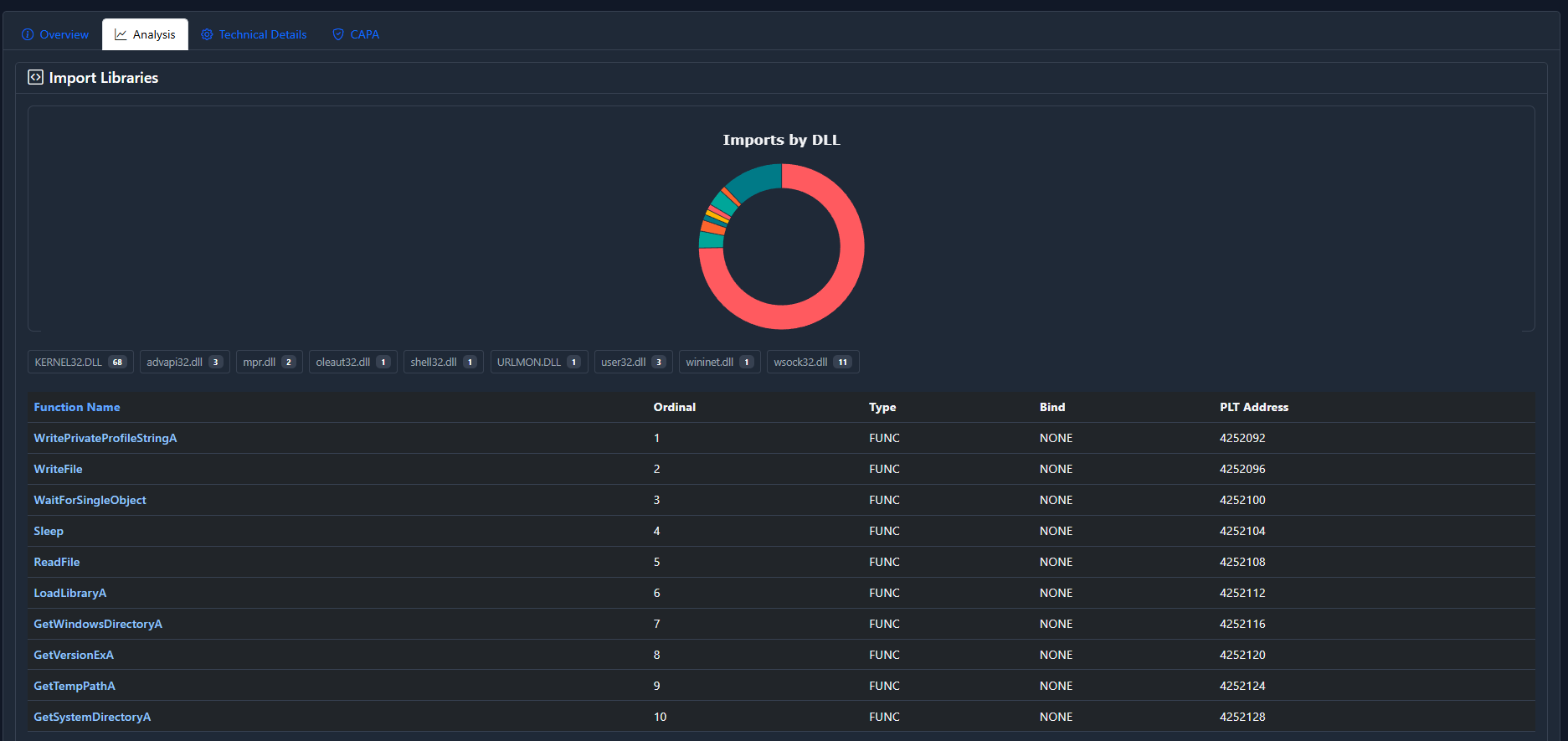
This generally breaks down which functions are imported from which DLL. This is not inherently useful in determining maliciousness, but it's fun.
Next, we hit the function categories which creates percentages of
where the groupings occur. 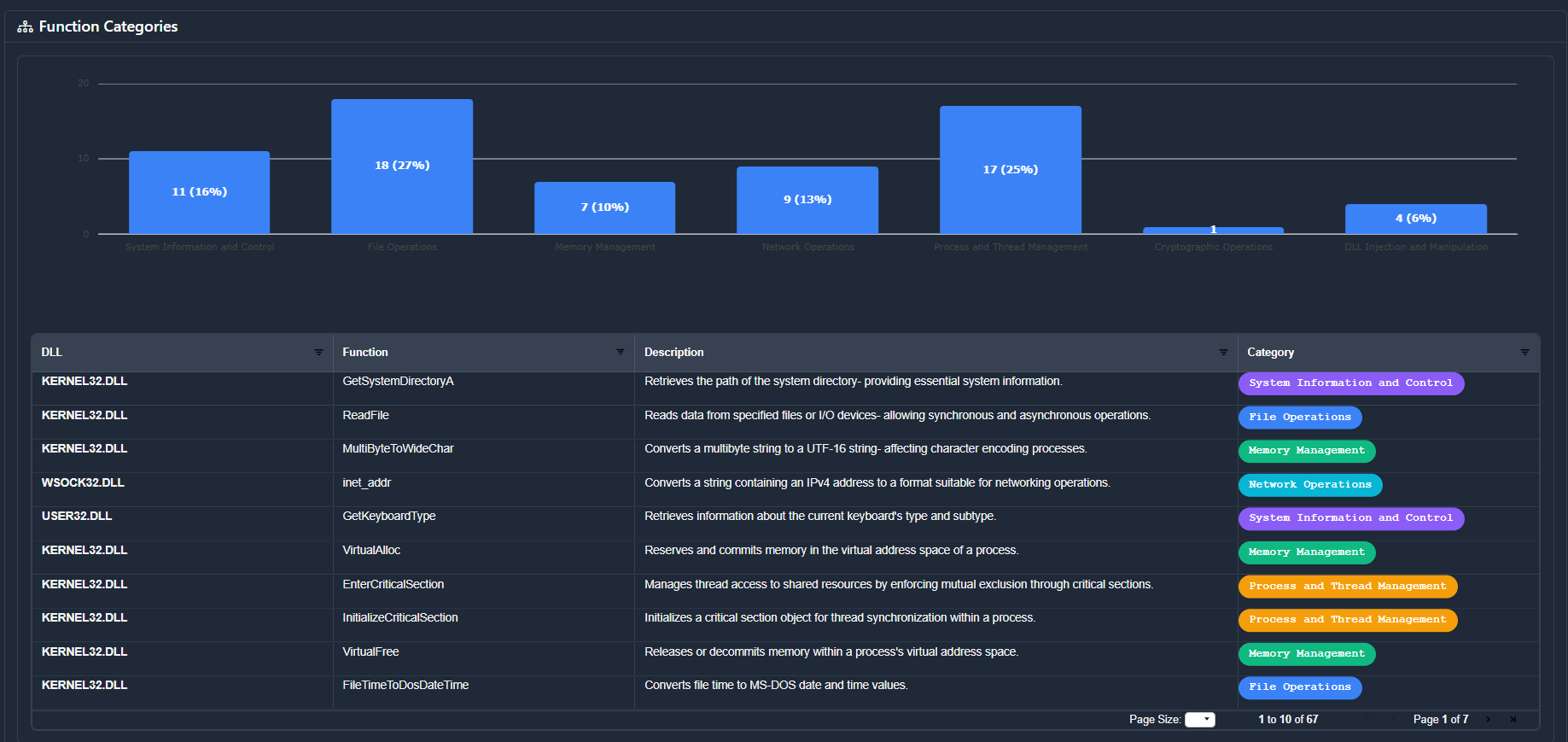
This has been discussed in the following posts:
Then after this we get to the same charts as the previous version.
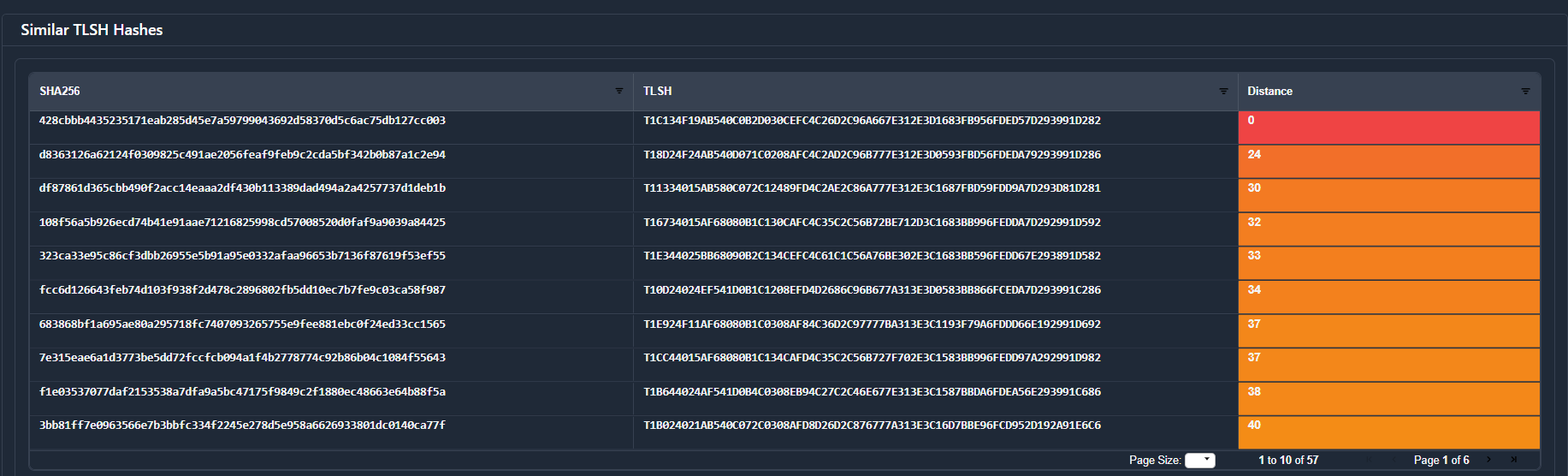
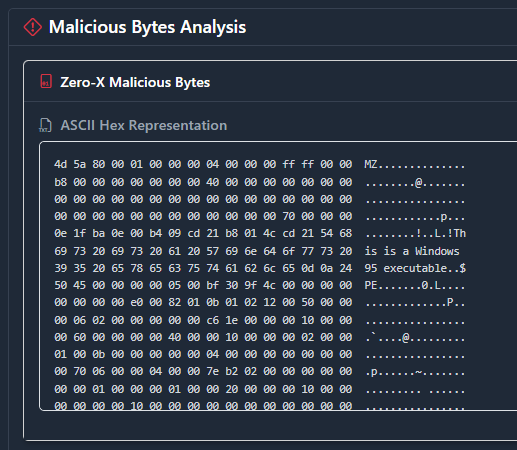
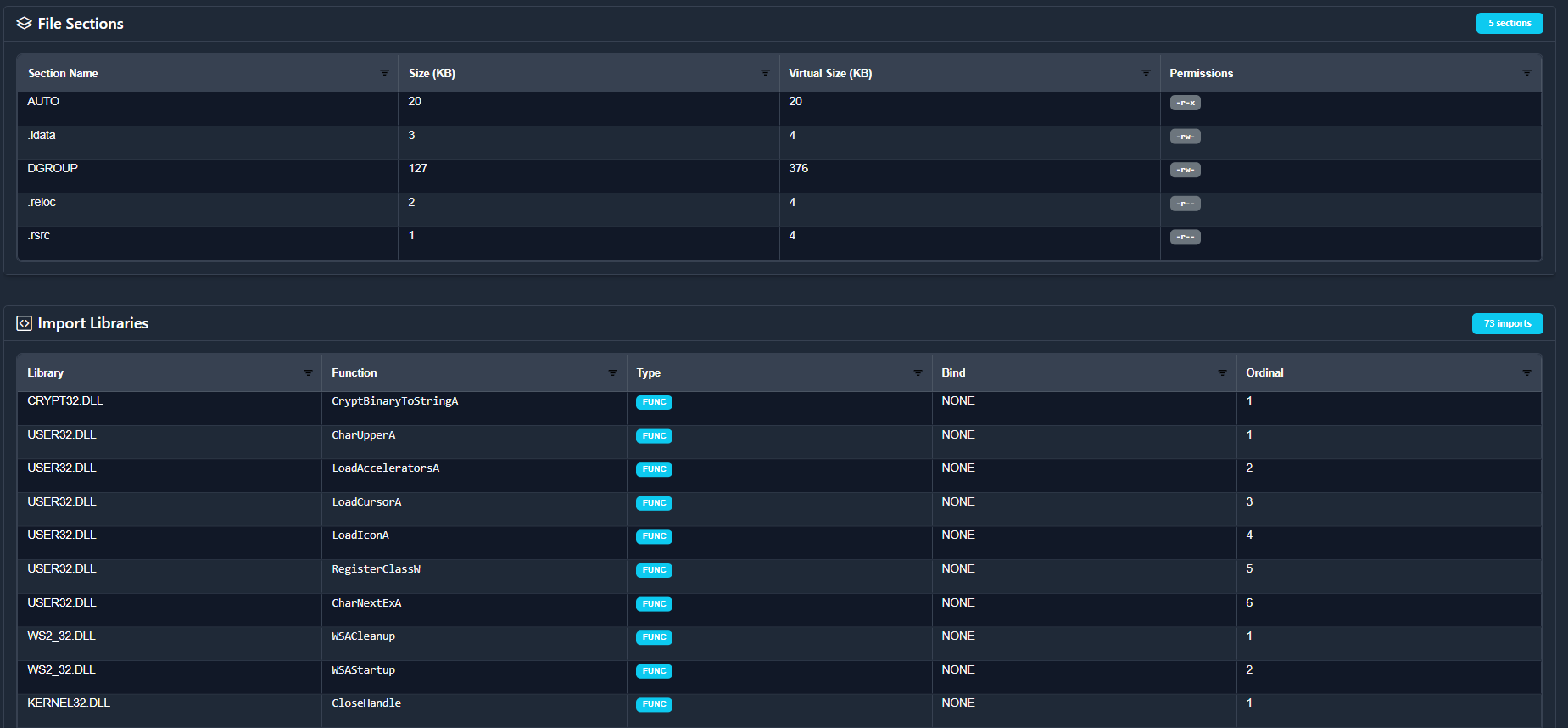
Going back to the tabs, if we go to the Technical Details, we get everything we'd expect like sections, optional headers, compilers, etc.
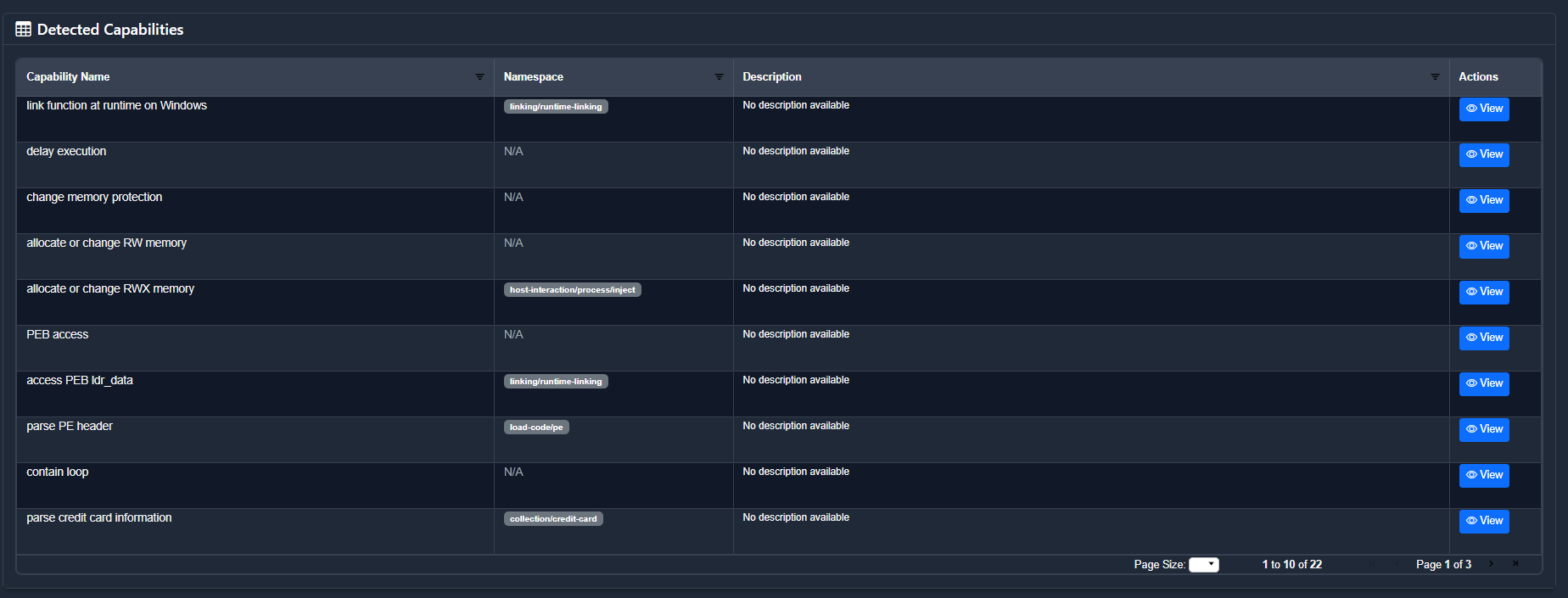
Finally, we get to the CAPA section which just visualises the output. In this sample, we have 22 matches and they're all viewable.
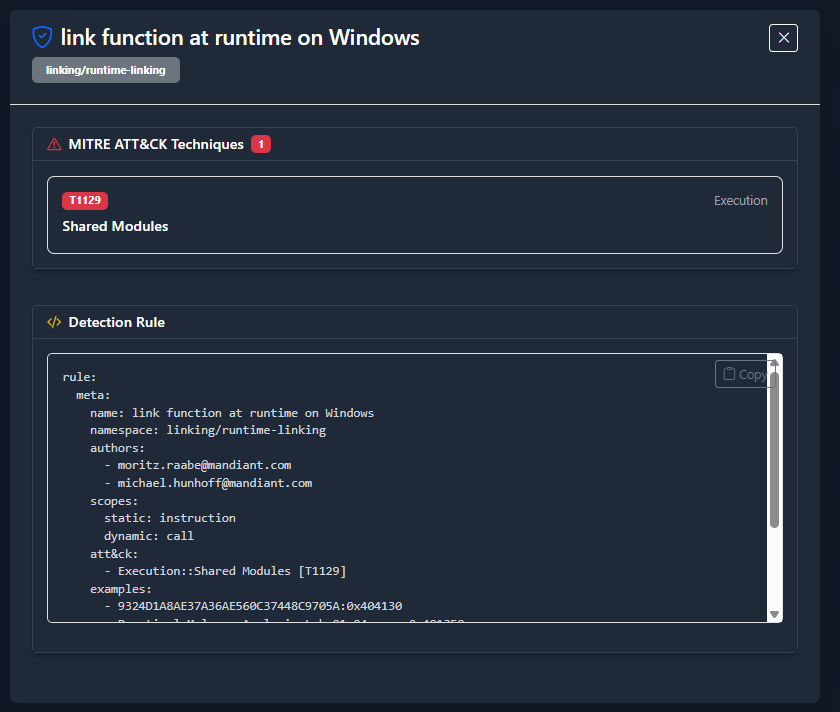
Clicking “view”:
And that's everything for this release. Again, not a single line of code written – enjoy the free XSS.
Future Improvements
If we look in the payload model, there are a few things which aren't shown. This is purely because I don't really know how I want to show them. For example, certificates:
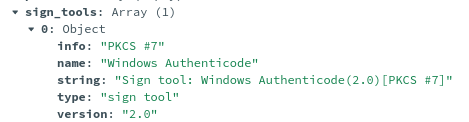
Another issue was strings. In some files, there were literally hundreds of thousands. So, I dump them to the citadel directory and set strings_file_path in the database. As there are some many, I currently don't know what to do with them.

Finally, functions. The same problem arises - there are way too many and I'm not too sure what to do with them at the moment:
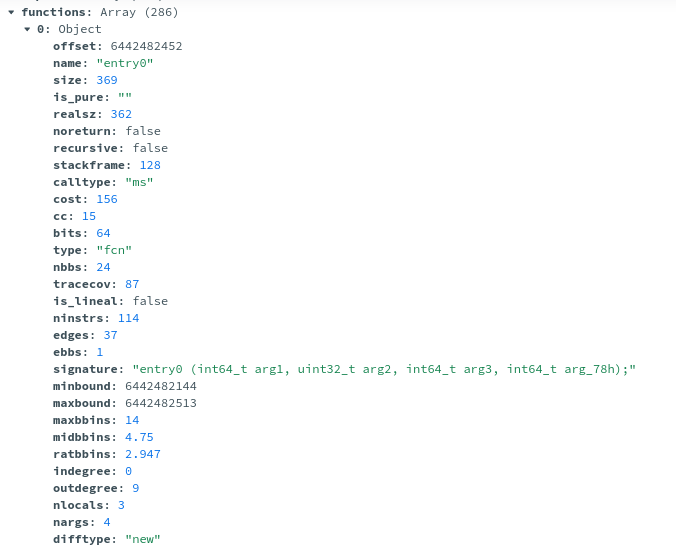
Problematic datapoints aside, I would like to have EMBER tell me why it rates a sample as malicious. Why did this one sample get a score of 1.0? which part of the feature set did it match on? Again, very difficult given the vectorised feature extraction, but it would be cool to know. A potential solution to this would be to use Feature Extraction with the feature_importance function from LightGBM.
I also have some code lying around using ETW as a sandbox, and a big memory scanner tool that would all hook in – but I want the static analysis to work well first. I am open to any suggestions, please let me know if you have any thoughts via X or GitHub.
Conclusion
Citadel: Binary Static Analysis Framework introduced the project and it worked well, but the UI was pretty meh and it wasn't really capable of being useful. This release introduced EMBER, a snazzy new UI, and an LLM summary to try and point you in a direction. In future releases, I want to continue to build on this as I think there's more that can be done overall.