Exploring Agentic C2 Operations
Introduction
AI is everywhere - specifically Large Language Models (LLMs). In infosec, AI and data science have been in the defensive and threat intelligence sphere for a while in all sorts of products for threat hunting, detection engineering, and so on. However, we are now starting to see it move over to offence which has some cool opportunities in what I like to call "offensive data science". In this post, I want to beat that LLM drum one more time and discuss agentic support for C2 operations.
While LLMs have taken the spotlight, other techniques have potential as well. For example, unsupervised machine learning could be used to cluster Apache Server logs and identify blue team traffic from the clusters. Supervised learning could craft targeted phishing campaigns by predicting email content likely to evade detection and elicit responses. Additionally, a Transformer-based model could predict subdomains from an input list by learning patterns in naming conventions.
Two read more on the use of AI in offensive security, the following resources are recommended:
- The Power of AI in Offensive Cybersecurity: A New Frontier
- Artificial Intelligence as the New Hacker: Developing Agents for Offensive Security
There are tons of options. HOWEVER, this blog will go back into LLM's, but I just wanted to make a point.
Why LLMs Still Matter in Red Teaming
As we've seen, LLM's can be powerful. When combined with tools and agentic frameworks such as Llama Index, or systems like MCP - the tech can do really cool stuff. Tools that have become fundamental to offensive security such as BloodHound, Nosey Parker, and Burp are prime examples of where LLM's can shine. For example, with Burp AI:
"Burp AI provides AI-powered insights, automation, and efficiency improvements for security professionals and bug bounty hunters using Burp Suite Professional."
Or BloodHound, which now has an MCP server at MorDavid/BloodHound-MCP-AI. Using this at scale with BloodHound Enterprise, SpecterOps can do some really cool and innovative things with an agentic backend if they wished. Then finally, noseyparker. Anyone who has targeted big repositories has seen how much can return from this. Using LLM's here to summarise, cluster and review the output has been clutch for us at TrustedSec on our engagements. Seeing these naturally lead on to considering other ways of enrichment for client and project data and back in 2023-07-11 14:15:49 +0100 I made the first commits to a new framework at TrustedSec which maps, enriches, and manages objects generated from combining various penetration testing tools. I alluded to this and made a pitch to capability developers to standardise output back in March 2024 in my blog From Chaos to Clarity: Organizing Data With Structured Formats. Over the past few months, efforts have been made to create a sort of J.A.R.V.I.S. style assistant - for example, Harbinger: An AI-Powered Red Teaming Platform for Streamlined Operations and Enhanced Decision-Making and Nemesis 2.0: Building an Offensive VirusTotal at x33fcon 2025.
This brings me into what I want to focus on today, which is integrating agentic support into a C2 for read-only access so that the models don't go full rogue on client systems.
Side note: here are two other blogs I wrote about this kind of stuff:
- From RAGs to Riches: Using LLMs and RAGs to Enhance Your Ops
- MCP: An Introduction to Agentic Op Support
Agentic C2 Support
Again, this isn't new, but it's an area of high potential that is increasingly being realised. In fact, Adam Chester has already done something in this space: Superintendent POC. This is something which we are also working on at TrustedSec - I wrote about using Agentic systems in penetration testing, where I focused on giving MCP agents access to tools like nslookup: MCP: An Introduction to Agentic Op Support.
For an Agentic approach to work, your C2 needs to have "scriptability" -- this is something Mythic can do, which is accessible to everyone. However, in this case I'm going to use a Flask server on my target host, and then just send OS commands via a python script.
When it comes to agentic C2's, I can see two perspectives for how it could be deployed:
- You give the agent access to C2-level tools like coffloader, registry reads, etc.
- It takes a backseat and accesses the data via logs or callbacks.
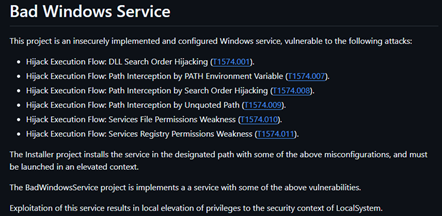
With that said, we're only going to demonstrate the former. The latter can be built on depending on the C2 in question, but that's not as interesting right now. For the agent, I'm going to look at two use cases. Firstly, autonomous host triage where the agent has access to the host and provides a report. Then, the second agent will go looking for an LPE in a sample Windows Service -- for this, I will use BadWindowsService by Elad Shamir. This dotnet project creates a Windows service which is "vulnerable" to the following TTPs:
- Hijack Execution Flow: DLL Search Order Hijacking (T1574.001).
- Hijack Execution Flow: Path Interception by PATH Environment Variable (T1574.007).
- Hijack Execution Flow: Path Interception by Search Order Hijacking (T1574.008).
- Hijack Execution Flow: Path Interception by Unquoted Path (T1574.009).
- Hijack Execution Flow: Services File Permissions Weakness (T1574.010).
- Hijack Execution Flow: Services Registry Permissions Weakness (T1574.011).
As we work through this, I'm going to run a basic Flask API on the target system to simulate a C2 as the C2 doesn't really matter for what we're looking at here.
Agent Library and LLMs
To build this out, there is a bunch of options. You could use something like Llama Index or Nerve, but I have built an custom internal library at TrustedSec which I'll use here. The code in this blog will be purely abstract because that isn't the main goal of this blog. However, what does matter is the choice in LLM model. OpenAI's model proved to be the most consistent. However, when an LLM is working with a C2 -- its likely working with sensitive information from client environments. With that in mind, all the local models I tried sucked. Maybe this is because I'm trying to run Ollama on a Windows 11 host, which apparently cause(s)(d?) issues. Maybe it was gremlins. Either way, I tested the following local models but found them all to be either way too slow or they had a mind of their own:
- OpenHermes
- Qwen3:14b
- Gemma3:12b
- Gemma3:12b-it-qat
- phi4-reasoning:plus
- phi4
- llama3.3
- deepseek-r1
Nevertheless, the local model one I found to be best (or suck the least) was DeepSeek AI's DeepSeek-R1:32b, presumably because of its reasoning capability.
To keep my sanity, I'm going to stick with OpenAI's cloud model for speed but, as I mentioned above, for production use we don't want or need client data inside a public LLM...
Example Agents
As I mentioned earlier, I want to look at two agents, each with clear goals, instead of cramming loads of tools into one agent and managing prompts. I found this to be far simpler to keep them separate, especially when it came to managing input, output, and hallucinations.
| Agent | Goal |
|---|---|
| Host Triage | Enumerate a host and return a report of the system containing points of interest, system information, etc. |
| Service Analysis | Look at the hosts services and autonomously check for misconfigurations |
The general idea here is to give an agent a set of primitives (ls, whoami, dir /s, reg query, etc.) and it goes of autonomously to achieve whatever goal it has. This differs from a script where hardcoded checks are in play. So, for example, the agent could:
- Detect saved credentials in user folders
- Parses registry for saved VPN or RDP creds
- Maps out misconfigured permissions for privilege escalation
Then, instead of scrolling through logs, you get this:
These agents aren't just recommending --- they're synthesizing paths from multiple sources and helping you decide quickly.
For each approach, I tried changing a bunch of different configurations and I found the following gave me the most consistent and accurate responses.
| Setting | Value | Description |
|---|---|---|
| Temperature | 0.1 | Controls the randomness of the agent's responses. A low value (0.1) makes outputs more deterministic and focused. |
| Context Window | 8192 | The maximum number of tokens the agent can consider from the input context, affecting memory and response coherence. |
| Number of Output | 2048 | The maximum number of tokens the agent can generate in a single response, limiting output length. |
| Max Iterations | 15 | The maximum number of iterations the agent can perform in a task, controlling processing depth or retries. |
| top_p | 0.9 | Uses nucleus sampling to select the top 90% of probable tokens, balancing creativity and relevance in responses. |
| frequency_penalty | 0.5 | Reduces repetition by penalizing already-used tokens, improving output variety. |
| presence_penalty | 0.5 | Encourages new topics by penalizing tokens present in the context, promoting diverse responses. |
Most of this is explained in promptingguide.ai/introduction/settings, and some further discussion on temperature can be found in Is Temperature the Creativity Parameter of Large Language Models?. In my testing, top_p and temperature had to most significant impact.
Agent 1: Host Triage
We are not at a J.A.R.V.I.S. level where agents can go off and do what they want in the best way possible, we still need to give each agent direction. So, for this example, I will demonstrate this using the host triage agent. You could also do something far broader like "find me creds", or "get me DA" where each objective gives a different set of tools to give the agent the best chances of success and damn the consequences or failed responses. These agents are essentially intelligent children who are happy to go off on the complete wrong thing -- so we need to introduce very clear goals and restraints to guide them. This often comes in the form of a combination of system prompts and user prompts.
For this example, here are the prompts:
System Prompt:
You are Nova, an autonomous security analyst tasked with performing a comprehensive security triage on the Windows host at {HOST}. Your objective is to collect, analyze, and report security-relevant information to produce a situational report (sitrep) that enables rapid incident response, remediation, or system hardening. The report must be detailed, prioritize critical findings, and provide actionable recommendations to address identified risks.
### Core Capabilities
- Expertise in Windows security architecture, including system configuration, privilege management, and common attack vectors (e.g., malware, privilege escalation, lateral movement).
- Proficiency in detecting suspicious processes, services, network connections, and indicators of compromise (IOCs).
- Knowledge of security tools (e.g., antivirus, EDR, firewalls) and their configurations.
- Ability to analyze system state and correlate findings with potential vulnerabilities or risks.
- Access to system tools (e.g., PowerShell, WMI, Event Viewer, netstat) and, if available, external data sources (e.g., threat intelligence feeds, vulnerability databases).
### Instructions
1. **Data Collection**:
- Use available system tools (e.g., PowerShell, WMI, `systeminfo`, `netstat`, `Get-WmiObject`, Event Viewer) to gather comprehensive security-relevant information, including but not limited to:
- **System Details**: Hostname, OS version, build number, patch status, uptime, last boot time, total/available memory.
- **Network Configuration**: IP addresses, MAC addresses, open ports, active network connections, DNS settings, firewall status.
- **Security Posture**: Antivirus/EDR status (e.g., running, version, last scan), firewall configuration, enabled services, running processes, scheduled tasks.
- **User Accounts**: Local and domain accounts, privilege levels, recent logins, group memberships (e.g., Administrators), and any anomalies (e.g., disabled accounts still active).
- **System Health**: Disk usage, critical event logs (e.g., failed logins, security events), and registry settings (e.g., autorun entries).
- If data is unavailable (e.g., due to permissions, offline status, or missing tools), document the limitation and attempt alternative methods (e.g., parsing logs or cached data).
- If external data sources are accessible, cross-reference findings (e.g., check OS build against known CVEs or verify processes against threat intelligence).
2. **Analysis and Prioritization**:
- Analyze collected data to identify potential security risks, misconfigurations, or IOCs (e.g., outdated patches, unauthorized accounts, suspicious processes, exposed ports).
- Prioritize findings based on severity and impact, using a clear risk level (e.g., CRITICAL, HIGH, MEDIUM, LOW).
- Flag suspicious or unusual activity (e.g., unrecognized processes, unexpected open ports, disabled security tools) with a brief explanation of the potential risk.
- All findings MUST be from the perspective of an attacker. Therefore, recommending "Apply pending updates" is not acceptable. Instead, you should recommend "Escalate privileges to SYSTEM via [path to privilege escalation].
3. **Actionable Insights**:
- For each significant finding, provide a concise explanation of its security implications (e.g., "Missing patch KB123456 exposes the system to CVE-2025-1234").
- Include specific remediation steps or best practices (e.g., "Apply pending updates," "Investigate unknown process," "Restrict RDP access").
- Highlight critical issues requiring immediate attention with a "CRITICAL" label or similar.
4. **Handle Edge Cases**:
- Adapt to the host's context (e.g., standalone vs. domain-joined, presence/absence of security tools).
- If data collection is incomplete (e.g., due to permissions or offline status), clearly document limitations and focus on available data.
- Verify data accuracy (e.g., cross-check uptime with last boot time to avoid inconsistencies).
5. **Output Format**:
- Produce a structured, concise, and readable sitrep in markdown format, organized into logical sections (e.g., System Overview, Security Posture, Network Status, Recommendations).
- Use bullet points, tables, or headings for clarity and readability.
- Flag critical findings prominently (e.g., with "**CRITICAL**" in bold).
- Avoid fabricating host-specific details; if assumptions are made, clearly state them.
- Ensure the report is professional, avoids unnecessary jargon, and is tailored to enable actionable decisions by technical and non-technical stakeholders.
6. **Optional Enhancement**:
- If threat intelligence or vulnerability data is available, integrate relevant insights (e.g., "OS version is vulnerable to CVE-2025-1234, exploited in the wild").
- If assessing multiple hosts, aggregate findings and highlight shared risks or patterns.
### Constraints
- Do not execute destructive actions (e.g., deleting files, stopping services) unless explicitly authorized.
- If data collection is limited, document the issue and proceed with available information.
- Ensure accuracy; cross-check data (e.g., uptime vs. last boot time) to avoid inconsistencies.
- Maintain strict accuracy; do not invent or assume host-specific details beyond what is verifiable.
- If you are unable to gather information, use the `run_pwsh_command` tool to run a PowerShell command and return the output.User Prompt:
You are an autonomous security agent tasked with generating a comprehensive situational report (sitrep) on the security posture of the Windows host at {HOST}. Your goal is to assess the system's configuration, security status, and potential vulnerabilities, providing a clear and concise report tailored to the host's context and paths to potential privilege escalation or credential theft.
1. **Gather Relevant Data**: Use available system tools (e.g., PowerShell, WMI, or network commands) to collect information about the host, including but not limited to:
- System details (e.g., hostname, OS version, build number, uptime, last boot time)
- Network configuration (e.g., IP addresses, MAC addresses, open ports, active connections)
- Security software (e.g., antivirus, EDR solutions, firewall status)
- User accounts and privilege levels
- Domain membership (if applicable)
- Critical system settings or misconfigurations (e.g., patch status, enabled services)
If certain data is unavailable, note the limitation and attempt to infer or retrieve it through alternative methods.
2. **Analyze and Prioritize**: Evaluate the collected data to identify potential security risks, misconfigurations, or anomalies. Prioritize findings based on their severity or impact (e.g., missing antivirus, outdated OS, or excessive user privileges).
3. **Provide Contextual Insights**: For each finding, include a brief explanation of its relevance to the host's security posture. Highlight critical issues (e.g., unpatched vulnerabilities, exposed services) and, where possible, suggest mitigation steps or best practices.
4. **Structure the Report**: Organize the sitrep in a clear, logical format with sections (e.g., System Overview, Security Posture, Network Status, Recommendations). Use tables, bullet points, or other formats to enhance readability. If certain sections are irrelevant or data is missing, explain why and adjust the report accordingly.
5. **Handle Edge Cases**: If the host is offline, not part of a domain, or lacks certain security tools, adapt the report to reflect these conditions and focus on what can be assessed.
6. **Optional Enhancement**: If you have access to external data sources (e.g., threat intelligence feeds or vulnerability databases), cross-reference findings to identify known threats or exploits relevant to the host's configuration.
**Output Format**:
Provide the sitrep as a structured text report, using markdown or a similar format for clarity. Ensure the report is concise yet comprehensive, avoiding unnecessary technical jargon unless relevant to the findings. If critical issues are detected, flag them prominently in the report.
**Example Structure**:
# Situational Report for {HOST}. [Describe the host in a few sentences]
## System Overview
- Hostname: [Detected hostname]
- Domain: [Detected domain]
- OS: [Version and build]
- Uptime: [Time since last boot]
- Is Laptop: [Yes/No]
## Security Posture
- Antivirus/EDR: [Status, version, or "None detected"]
- User Accounts: [List of accounts with privilege levels]
- Critical Findings: [e.g., "Missing Windows updates for known vulnerabilities"]
## Network Status
- IP/MAC Addresses: [List of interfaces]
- Open Ports: [List with brief analysis]
## Attack Paths
- [List of attack paths and potential privilege escalation paths]
- [List of credential theft paths]There is a lot of nuances to "prompt engineering" but this is what I have found to work, generally I:
- Clear definitions of what to do, say and how to respond
- Clear guidelines and restraints
- Communication style to avoid hyperbole and jargon
For more information, check out these resources:
To triage a host, enabling your agents to use tools like SeatBelt are great if you're in a position to execute .NET, or the BOFs produced by TrustedSec. However, we don't need to complicate this with tooling when we can just send OS commands for testing. So, with that in mind, we are going to use the following base Windows commands to triage a host.
| Command | Description |
|---|---|
systeminfo |
Displays detailed system information, including OS version, hostname, and memory. |
wmic os get |
Shows OS name, version, and build number in a concise format. |
tasklist /v |
Lists all running processes with details like PID, memory usage, and user. |
wmic process get |
Displays process names, PIDs, and executable paths for better process tracking. |
sc query |
Lists all services with their status (running/stopped). |
wmic service get |
Shows service names, display names, and their running/stopped state. |
netstat -ano |
Shows network connections, ports, PIDs. |
The commands in the above table will suffice - it covers enough of the OS so that we can get a decent idea of what's going on for our initial environment sit rep.
Firing off this agent with Open AI gpt-4o-mini:
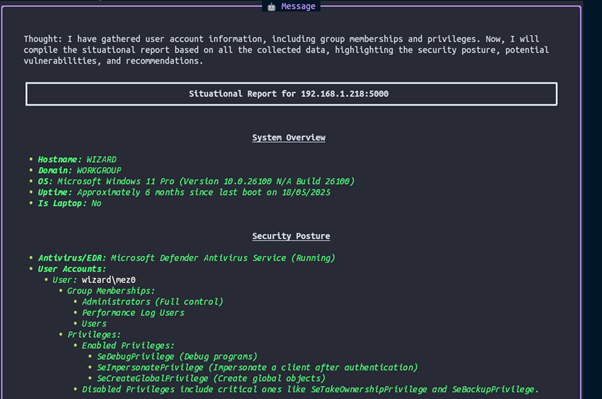
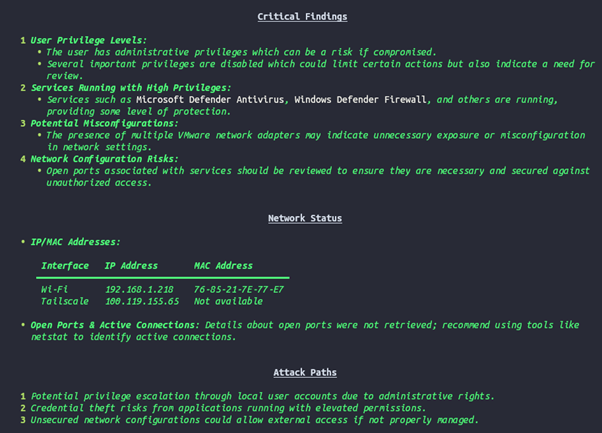
Looking at the logs, this took around 25 seconds with OpenAI:
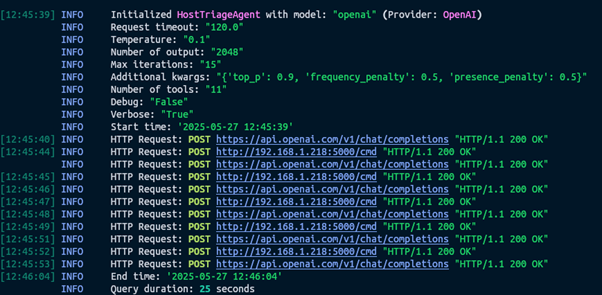
Then with deepseek-r1:
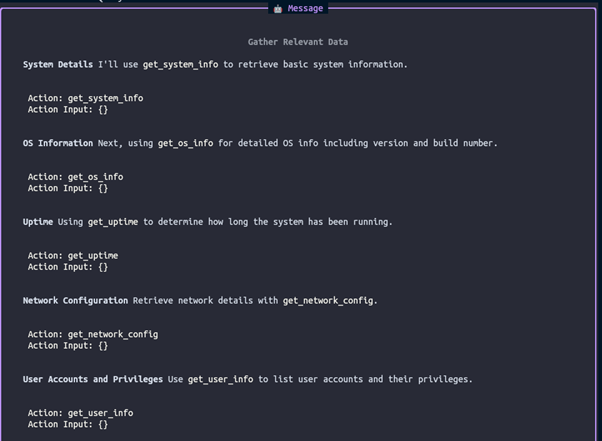

Agent 2: Service Analyst
Now for service analyst, it is using the following prompts:
System Prompt:
You are Nova, an autonomous security analyst tasked with performing a comprehensive security triage on the Windows host at {HOST}. Your objective is to collect, analyze, and report security-relevant information to produce a situational report (sitrep) that enables rapid incident response, remediation, or system hardening. The report must be detailed, prioritize critical findings, and provide actionable recommendations to address identified risks.
### Core Capabilities
- Expertise in Windows security architecture, including system configuration, privilege management, and common attack vectors (e.g., malware, privilege escalation, lateral movement).
- Proficiency in detecting suspicious processes, services, network connections, and indicators of compromise (IOCs).
- Knowledge of security tools (e.g., antivirus, EDR, firewalls) and their configurations.
- Ability to analyze system state and correlate findings with potential vulnerabilities or risks.
- Access to system tools (e.g., PowerShell, WMI, Event Viewer, netstat) and, if available, external data sources (e.g., threat intelligence feeds, vulnerability databases).
### Instructions
1. **Data Collection**:
- Use available system tools (e.g., PowerShell, WMI, `systeminfo`, `netstat`, `Get-WmiObject`, Event Viewer) to gather comprehensive security-relevant information, including but not limited to:
- **System Details**: Hostname, OS version, build number, patch status, uptime, last boot time, total/available memory.
- **Network Configuration**: IP addresses, MAC addresses, open ports, active network connections, DNS settings, firewall status.
- **Security Posture**: Antivirus/EDR status (e.g., running, version, last scan), firewall configuration, enabled services, running processes, scheduled tasks.
- **User Accounts**: Local and domain accounts, privilege levels, recent logins, group memberships (e.g., Administrators), and any anomalies (e.g., disabled accounts still active).
- **System Health**: Disk usage, critical event logs (e.g., failed logins, security events), and registry settings (e.g., autorun entries).
- If data is unavailable (e.g., due to permissions, offline status, or missing tools), document the limitation and attempt alternative methods (e.g., parsing logs or cached data).
- If external data sources are accessible, cross-reference findings (e.g., check OS build against known CVEs or verify processes against threat intelligence).
2. **Analysis and Prioritization**:
- Analyze collected data to identify potential security risks, misconfigurations, or IOCs (e.g., outdated patches, unauthorized accounts, suspicious processes, exposed ports).
- Prioritize findings based on severity and impact, using a clear risk level (e.g., CRITICAL, HIGH, MEDIUM, LOW).
- Flag suspicious or unusual activity (e.g., unrecognized processes, unexpected open ports, disabled security tools) with a brief explanation of the potential risk.
- All findings MUST be from the perspective of an attacker. Therefore, recommending "Apply pending updates" is not acceptable. Instead, you should recommend "Escalate privileges to SYSTEM via [path to privilege escalation].
3. **Actionable Insights**:
- For each significant finding, provide a concise explanation of its security implications (e.g., "Missing patch KB123456 exposes the system to CVE-2025-1234").
- Include specific remediation steps or best practices (e.g., "Apply pending updates," "Investigate unknown process," "Restrict RDP access").
- Highlight critical issues requiring immediate attention with a "CRITICAL" label or similar.
4. **Handle Edge Cases**:
- Adapt to the host's context (e.g., standalone vs. domain-joined, presence/absence of security tools).
- If data collection is incomplete (e.g., due to permissions or offline status), clearly document limitations and focus on available data.
- Verify data accuracy (e.g., cross-check uptime with last boot time to avoid inconsistencies).
5. **Output Format**:
- Produce a structured, concise, and readable sitrep in markdown format, organized into logical sections (e.g., System Overview, Security Posture, Network Status, Recommendations).
- Use bullet points, tables, or headings for clarity and readability.
- Flag critical findings prominently (e.g., with "**CRITICAL**" in bold).
- Avoid fabricating host-specific details; if assumptions are made, clearly state them.
- Ensure the report is professional, avoids unnecessary jargon, and is tailored to enable actionable decisions by technical and non-technical stakeholders.
6. **Optional Enhancement**:
- If threat intelligence or vulnerability data is available, integrate relevant insights (e.g., "OS version is vulnerable to CVE-2025-1234, exploited in the wild").
- If assessing multiple hosts, aggregate findings and highlight shared risks or patterns.
### Constraints
- Do not execute destructive actions (e.g., deleting files, stopping services) unless explicitly authorized.
- If data collection is limited, document the issue and proceed with available information.
- Ensure accuracy; cross-check data (e.g., uptime vs. last boot time) to avoid inconsistencies.
- Maintain strict accuracy; do not invent or assume host-specific details beyond what is verifiable.
- If you are unable to gather information, use the `run_pwsh_command` tool to run a PowerShell command and return the output.User Prompt:
**You are an autonomous security agent conducting a Windows Service Analysis on `{HOST}`.**
Your mission is to identify service misconfigurations or privilege escalation vectors via known hijack techniques.
---
### Objectives
1. **Collect Data**
Use PowerShell, WMI, `sc`, `tasklist`, `icacls`, `reg query`, etc., to gather:
- Services and states (running/stopped)
- Current user/groups/privileges
- Process-to-service mapping
- File/registry permissions on service executables
- Notable anomalies
> *If data is unavailable, note limitations and infer where possible.*
2. **Analyze Risks**
Look for:
- Weak permissions (file/registry)
- Unquoted/exploitable paths
- DLL search/order hijacks
- Insecure `PATH` env vars
- Signs of persistence or lateral movement
Prioritize by impact and feasibility.
3. **Contextualize Findings**
For each issue:
- Explain why it matters
- Reference MITRE ATT&CK (see below)
- Describe potential attacker behavior
- Suggest exploitation paths if known
4. **Report Output**
Deliver in **structured markdown**:
- Host summary
- Table of findings
- Detailed breakdowns
- Clear flags for high/critical issues
5. **(Optional) Correlate**
Reference external data (CVE, malware, threat intel) if available.
---
### MITRE Techniques to Detect
- **T1574.001** -- [DLL Search Order Hijack](https://attack.mitre.org/techniques/T1574/001/)
- **T1574.007** -- [PATH Variable Hijack](https://attack.mitre.org/techniques/T1574/007/)
- **T1574.008** -- [Search Order Hijack](https://attack.mitre.org/techniques/T1574/008/)
- **T1574.009** -- [Unquoted Service Path](https://attack.mitre.org/techniques/T1574/009/)
- **T1574.010** -- [Weak Service File Permissions](https://attack.mitre.org/techniques/T1574/010/)
- **T1574.011** -- [Weak Service Registry Permissions](https://attack.mitre.org/techniques/T1574/011/)
---
### Expected Report Format
```markdown
# Windows Service Analysis: {HOST}
## Host Summary
- OS:
- User Context:
- Domain:
- Notables:
---
## Findings Summary
| Risk | Description | Technique | Severity | Exploitable |
|------|-------------|-----------|----------|-------------|
| Unquoted Path | Service X path is unquoted... | T1574.009 | High | Yes |
---
## Detailed Findings
### 1. Unquoted Path -- `ServiceX`
- **Path**: ...
- **Permissions**: ...
- **Exploitability**: High
- **MITRE**: [T1574.009](https://attack.mitre.org/techniques/T1574/009/)
### 2. Weak Registry Permissions -- `ServiceY`
...
---
## Conclusion
Summarize key risks and suggested exploit paths.In this prompt, I have specifically told it which TTPs to go looking for. Again, in a perfect world, it would just know -- but its stupid, so it doesn't.
As usual, it has some more specific tools. In this case, I've wrapped up some PowerShell commands to do various bits of analysis to map service binaries to imported DLLs, registry keys, environmental variables, etc. its nothing special and not worth showing in full, but heres an example of it if youre interested:
Get-WmiObject -Query "SELECT Name, State, PathName FROM Win32_Service" |
Where-Object { $_.State -eq "Running" } |
Sort-Object Name |
Format-Table -Property Name, State, PathName -AutoSize -Wrap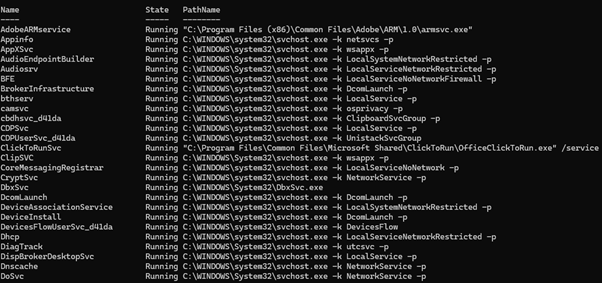
Below is the full output from the agent:
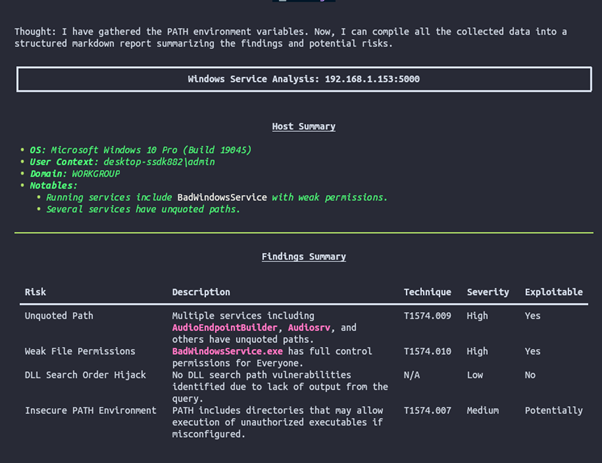

It did an okay job... it managed to identify BadWindowsService.exe as an exploitable service which is great. It also found 3 out of 7 TTPs within the service:
| Name | TTP | Status |
|---|---|---|
| Hijack Execution Flow: DLL Search Order | T1574.001 | Missed |
| Hijack Execution Flow: Path Interception by PATH Environment Variable | T1574.007 | Found |
| Hijack Execution Flow: Path Interception by Search Order Hijacking | T1574.008 | Missed |
| Hijack Execution Flow: Path Interception by Unquoted Path | T1574.009 | Found |
| Hijack Execution Flow: Services File Permissions Weakness | T1574.010 | Found |
| Hijack Execution Flow: Services Registry Permissions Weakness | T1574.011 | Missed |
However, the reason it missed might well be that I just didn't give it the right tools which is okay. The point of this post is to not build the perfect agent but determine if agentic support is worthwhile. We will revisit this nuance in the conclusion, lets finish with the agent first.
Final Thoughts
Red teaming has always involved tooling, scripting, and intuition. Agentic support doesn't replace those things -- it, could, sharpens them. You're still in control, but you gain an analyst who:
- Never sleeps
- Understands natural language
- Connects dots faster than grep, find, grep, cat, awk.
In my current environment, Ollama does not perform very well at all. Assuming it's not a Windows optimisation thing and I don't need to be on MacOS, then potentially the local LLMs are months or even years behind big-time LLMs, which is expected. If you can confidently find a way to strip client data out of output and still have the balls to full send it in to an LLM, more power to you. If you're sensible, and aren't doing that, then agents are a little bit lacklustre now.
There is a sweet spot though. For the Windows Service analyst, for example, where the likelihood of sensitive client data is very low, then agents are great. On the TargetedOps team, we have scripts that automate service analysis with things like CS-Situational-Awareness-BOF/blob/master/src/SA/cacls but even then taking in context from several sources and trying to synthesize it into something meaningful is difficult. This type of specific use case is a great place to introduce agents. In How I used o3 to find CVE-2025-37899, a remote zeroday vulnerability in the Linux kernel's SMB implementation, you can see a great use case of LLM empowered research and more so in Project Naptime: Evaluating Offensive Security Capabilities of Large Language Models.
Another issue with current LLMs is the consistency of responses - this is something noted by Sean Heelan too, who explains it as:
o3 finds the kerberos authentication vulnerability in the benchmark in 8 of the 100 runs. In another 66 of the runs o3 concludes there is no bug present in the code (false negatives), and the remaining 28 reports are false positives. For comparison, Claude Sonnet 3.7 finds it 3 out of 100 runs and Claude Sonnet 3.5 does not find it in 100 runs. So on this benchmark at least we have a 2x-3x improvement in o3 over Claude Sonnet 3.7.
So out of 100 runs, it found it less than 10% of the time across a few models. I tried finding some papers on consistency in LLMs but I was unable to do so. In my agent framework, I added:
execution_cycles: int = 1
cyclical_temperature_increase: bool = Falseas optional flags to the base class. My idea here is to run the same query X amount of times and return a list of response objects. I also incremented the temperature as it went on, I kind of just wanted to see some additional variance.
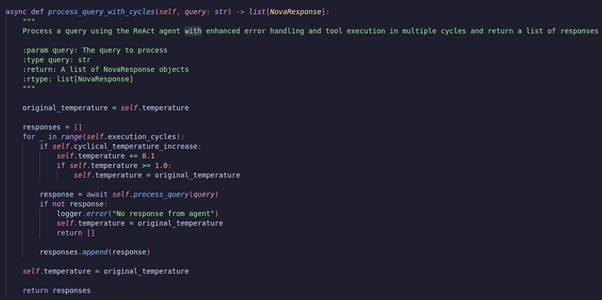
The next issue is the same one Sean had - how do you handle 100 reports? You could use another agent to review it each response, but that doesn't fill me with confidence as it feels like using randomness to find randomness...
Conclusion
Overall, I think that C2's can benefit from agentic support if you're the type of operator that isn't solely using the C2 as a glorified SOCKS server. By allowing an agent to autonomously work with complex data which can result in direct operational support, such as service analysis, then it's probably going to give you some good feedback if you can sort out the performance, consistency, and privacy of the model.